
Ei pessoal, nessa edição do PET Redação iremos falar sobre Web Scraping. Constantemente precisamos extrair informações de sites para fazer análises e, comumente, isso é feito manualmente. Utilizando a técnica de Web Scraping, esse processo se torna muito mais rápido e eficiente, automatizado. Ele é uma técnica para extrair informações importantes de algum site que serão analisadas futuramente. Essas podem auxiliar na tomada de decisões, principalmente de marketing. Nesta redação, vamos conhecer um pouquinho mais sobre essa técnica e como trabalhar com ela na linguagem Python.
Para trabalharmos com Web Scraping precisamos conhecer o básico das tags HTML, pois estaremos buscando os dados que se encontram nelas. Para esta redação, abra o site da Universidade e tecle “F12”. Ao fazermos isso, temos acesso ao código HTML do site e podemos verificar que há tags “div”, “span”, “main”, dentre outras.
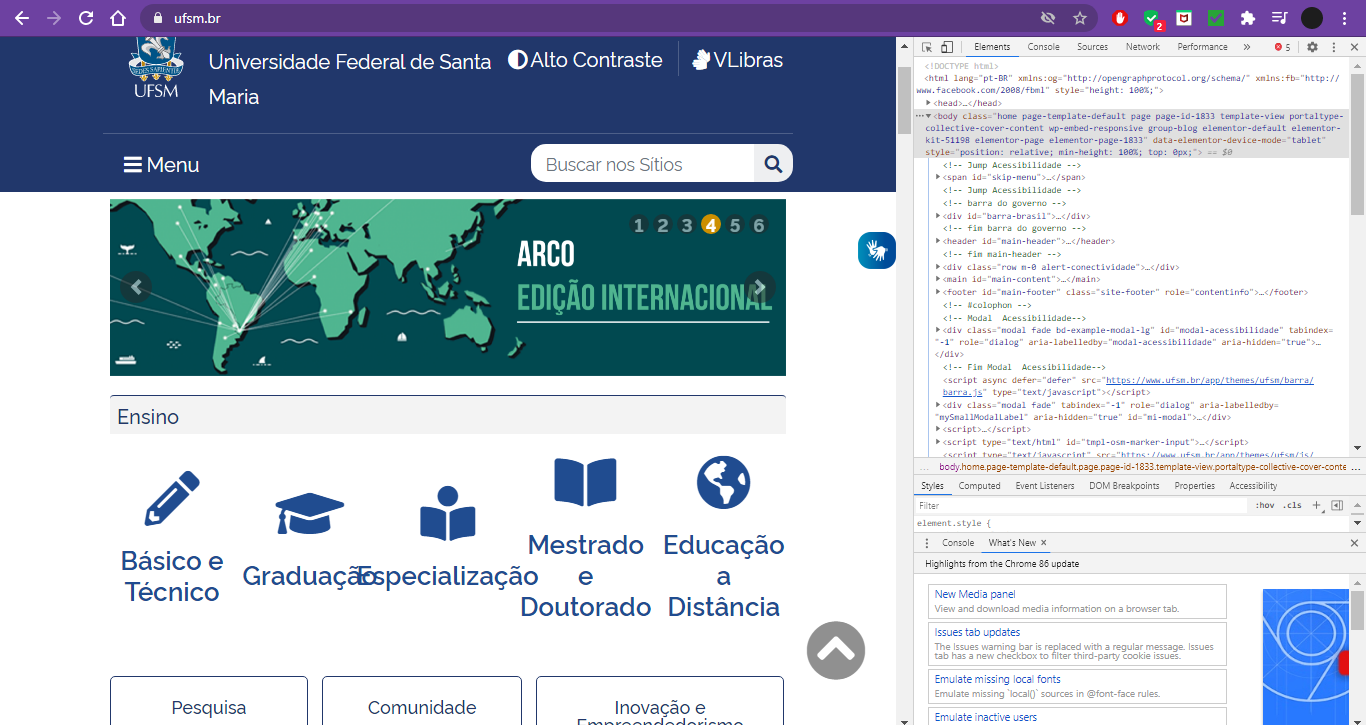
Ao abrirmos o menu de inspeção da página em “F12”, podemos ver o menu de opções na parte superior. Ao clicar no ícone da seta, destacado na figura abaixo, podemos mover o mouse pelos elementos da página e no menu à direita, será exibido o elemento HTML ao qual ele pertence. Precisaremos desta informação quando buscarmos os dados em nosso código.
![]()
Indo para o código, primeiro precisamos atender alguns requisitos antes de começar a trabalhar com o Python. Precisamos ter instalado o Python 3 e algumas bibliotecas:
- Requests, que serve para a execução de requisições HTTP;
- Beautifulsoup, que será responsável pela extração de dados nos arquivos HTML; e
- Pandas, que serve para armazenar, limpar e salvar os dados em forma de tabela.
Instalando Python 3:
- Se você usa Windows, basta baixar o instalador e seguir as etapas.
- No Linux, basta usar o comando no terminal:
$ sudo apt-get install python3
Instalando as Bibliotecas:
- Windows: No cmd (modo administrador) use os comandos:
$ python -m pip install requests
$ python -m pip install beautifulsoup4
$ python -m pip install pandas
- Linux:
$ sudo pip3 install requests
$ sudo pip3 install beautifulsoup4
$ sudo pip3 install pandas
Observação: note que você vai precisar do gerenciador de pacotes pip. Se você não tiver, use o comando $ sudo apt-get install python3-pip
Com tudo ok, podemos prosseguir para o desenvolvimento do código. O objetivo nesta redação é buscar os eventos que aparecem na página inicial do site da Universidade, comentado anteriormente. Nesta redação, por motivos de organização, iremos dividir o código em três arquivos: WebScraper-EventsUFSM.py (o arquivo principal), SearchEvent.py e GetSoup.py. Eles serão explicados ao longo da redação.
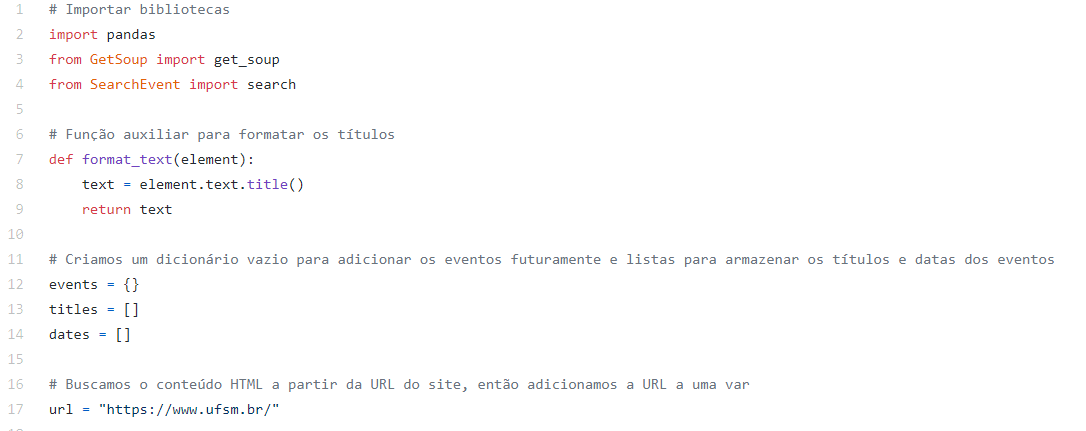
Iniciando com o arquivo principal, adicionamos as bibliotecas que iremos utilizar. A seguir, como iremos buscar o conteúdo HTML a partir da URL do site, adicionamos a URL a uma variável no código.
Agora, precisamos utilizar a biblioteca BeautifulSoup para extrair os dados. Essa é a função do arquivo GetSoup.py referenciado anteriormente. Novamente, precisamos importar as bibliotecas que iremos utilizar, que, além da BeautifulSoup, inclui a Requests. Observe a imagem abaixo:
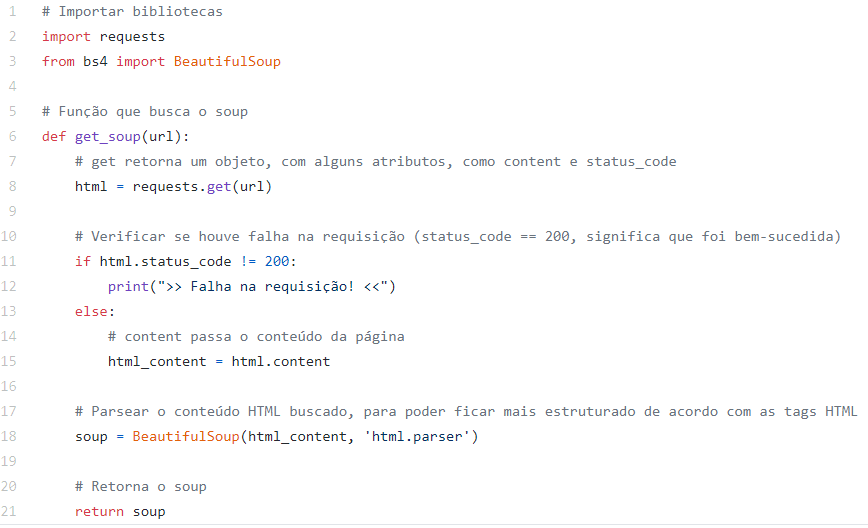
Criamos uma função que será referenciada no arquivo WebScraper-EventsUFSM.py. Ela recebe como parâmetro a url que definimos anteriormente. Com o método “get” da biblioteca requests, conseguimos como retorno um objeto que possui o conteúdo da página (content) bem como o estado da requisição (status_code), por exemplo. Aproveitando esse retorno, na linha 11 verificamos se houve falha na requisição – se tudo correr certo, retornará o código 200 e podemos salvar o conteúdo da página, do contrário, precisamos informar que ocorreu um problema (linha 12).
A seguir, estamos utilizando a biblioteca BeautifulSoup para transformar o conteúdo que buscamos com o método “get” para que ele fique mais estruturado como as tags HTML para que possamos manipulá-lo mais facilmente. Por fim, retornamos esse valor obtido para quem chamou a função.
Falando em quem chamou a função get_soup, vamos voltar ao arquivo WebScraper-EventsUFSM.py. Como é possível ver na imagem abaixo, criamos uma variável “soup” para receber o retorno da função.

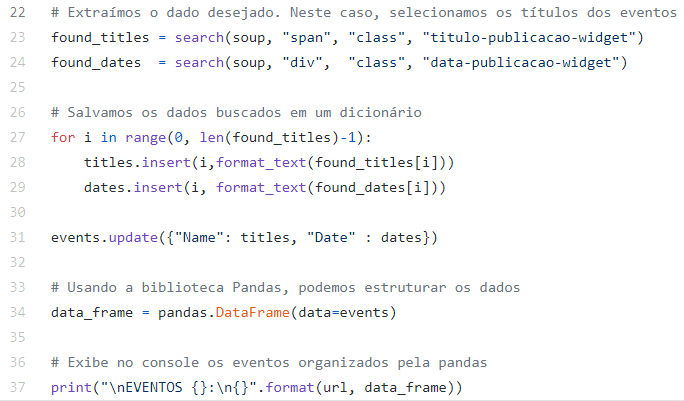
Agora, tendo o HTML da página, podemos buscar o trecho que queremos da página. A função search, que pode ser vista na imagem anterior, se refere ao último arquivo que estamos desenvolvendo: SearchEvent.py. Neste, estamos apenas criando uma função que irá buscar, por meio do método “findAll”, da biblioteca BeautifulSoup, todos os elementos que se encaixam na descrição passada como parâmetro (tag, identifier e desc) e retorná-los para o responsável por chamar a função. Na imagem abaixo, podemos ter uma ideia melhor de como isso é feito:

Observação: o método findAll retorna todas as ocorrências dos elementos especificados, diferentemente do método find, que retorna apenas a primeira.
Para finalizar, voltando ao arquivo principal, criamos um laço para formatar as informações e, a seguir, salvamos esses dados em um dicionário. Note que a função “format_text” foi criada apenas para buscar o texto do conteúdo e colocá-lo com formatação de títulos. O seu corpo pode ser visto na figura 3. Estando o dicionário pronto, utilizamos a biblioteca pandas para salvar esses arquivos em um data frame e exibi-los em formato de tabela.
E pronto! Está pronto o seu Web Scraper! Os arquivos comentados nesta redação se encontram no GitHub. Neste link se encontram outros exemplos, como WebScraper-BusSchedule.py, onde os dados são extraídos de uma tabela (no link), e, por meio da biblioteca pandas, são salvos em um dicionário e também como um arquivo json.

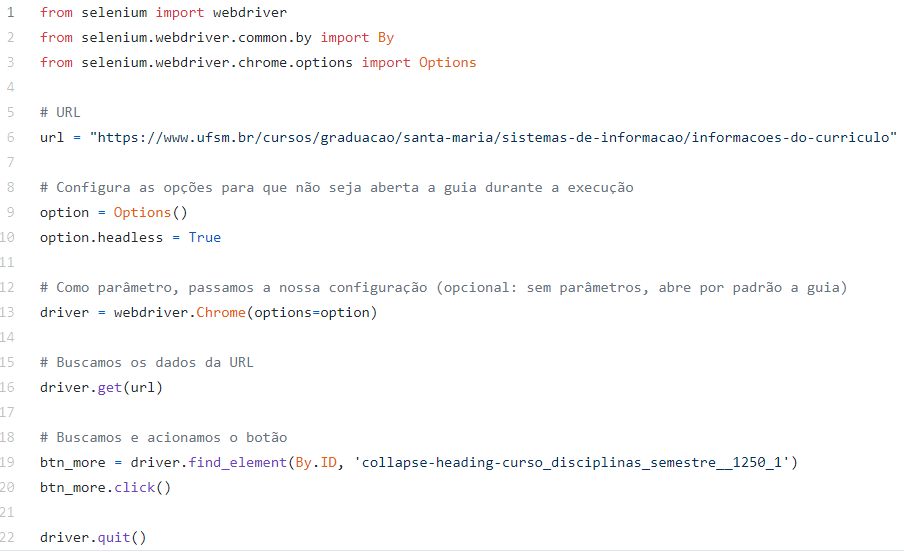
Outro exemplo, é o ExampleClick.py, onde, através do Python, é simulado um evento de click de mouse. Isso pode ser útil quando queremos interagir com a página para buscarmos nossas informações.
Como visto nessa redação, há muitas possibilidades para se trabalhar com Web Scraping em Python, este é apenas o começo. Essa técnica está se tornando cada vez mais importante na atualidade e é interessante aprendê-la. Apesar disso, lembre-se de usá-la com cuidado e responsabilidade, não se esqueça de estudar os termos de serviço do site em que está buscando seus dados nem as leis do local onde o mesmo está hospedado! Bons estudos.
Referências:
https://medium.com/data-hackers/como-fazer-web-scraping-em-python-23c9d465a37f
https://www.pluralsight.com/guides/web-scraping-with-beautiful-soup
http://www.compjour.org/warmups/govt-text-releases/intro-to-bs4-lxml-parsing-wh-press-briefings/#extracting-text-from-soup
https://dicasdepython.com.br/pandas-como-construir-um-dataframe-a-partir-de-um-dicionario/
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html
https://medium.com/machina-sapiens/raspagem-de-dados-com-python-e-beautifulsoup-1b1b7019774c
https://pt.stackoverflow.com/questions/323349/como-apertar-o-bot%C3%A3o-de-um-site-em-python
Raíssa Arantes


