
Fala pessoal! Esta edição do PET-Redação traz para vocês algumas bibliotecas importantes que irão ajudá-los em seus desenvolvimentos que utilizam a linguagem Python. Vamos começar?
Vamos começar pelos conceitos básicos. O que é uma biblioteca na computação: uma coleção de códigos voltados a resolver um determinado tipo de problema. Nesse contexto, vamos explorar algumas dessas coleções que podem ser úteis para plotar gráficos, trabalhar com imagens, etc.
Nesse sentido, essa redação apresentará algumas bibliotecas da linguagem e alguns de seus recursos e usos, detalhando alguns usos práticos de duas delas.
Pillow
Essa biblioteca, a Python Imaging Library, adiciona recursos de processamento de imagem interpretador Python, oferecendo suporte a formatos de arquivos e recursos para processamento de imagem.
Com ela é possível abrir e editar arquivos de imagem, criar miniaturas/thumbnails, inserir filtros, dentre outras funcionalidades.
Para utilizá-la, é necessária sua instalação: pip install Pillow. Nesta redação, será demonstrado um uso bem básico, para dar uma introdução: aplicando os filtros disponíveis pela biblioteca.
Primeiro é realizada a sua importação (from PIL import Image, ImageFilter) e a abertura da imagem desejada, através do comando Image.open(“caminho_da_imagem.extensão”). Com este comando, é possível abrir o arquivo que irá ser trabalhado. A seguir, utilizando o método filter, se passa por parâmetro o filtro escolhido a ser aplicado na sua imagem. Os filtros disponíveis são: blur, contour, detail, edge_enhance, edge_enhance_more, emboss, find_edges, smooth, smooth_more e sharpen.
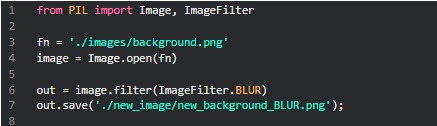
Após essas etapas, são salvas as modificações através do método save(). Para visualizar a alteração antes de salvar, poderia-se utilizar o método show(), a partir da nossa imagem alterada: out.show(). As alterações podem ser observadas abaixo. Simples, não?

É importante saber também que o objeto imagem possui alguns atributos, como filename (nome do arquivo), format (qual o formato da imagem), mode (que retorna o tipo de pixel utilizado, como CMYK, RGB, etc.), size, width, height, info (dicionário referente a dados relacionados à imagem) e palette (a paleta de cores, se houver).
A Pillow ainda fornece diversas outras funcionalidades como “resize()” (alterar tamanho), “rotate()” (rotacionar), “thumbnail(size)” (criar thumbnail), “merge()” (sobrepor/colar imagens), etc. Não deixe de conferir sua documentação para descobrir outros usos que essa biblioteca nos fornece! https://pillow.readthedocs.io/en/stable/
Beautiful Soup
Em redações anteriores essa biblioteca já foi comentada. Ela é ótima para realizar Web Scraping, extraindo as partes desejadas de um arquivo XML ou HTML. A Beautiful Soup se baseia em analisadores Python populares, como lxml e html5lib, permitindo que se experimente diferentes estratégias de análise.
Indo um pouco além do seu uso na redação de Web Scraping, o BeautifulSoup possui algumas outras funcionalidades. Por exemplo,
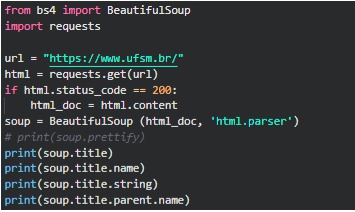
(note que utilizou-se a requests para obter o conteúdo html da página. A BeautifulSoup apenas divide esse conteúdo de acordo com o que desejarmos para realizar análise e scraping)
Na figura acima, soup recebe um objeto, que pode possuir algumas características. Ao chamarmos soup.title, teremos como retorno o que for interpretado como a tag <title> no nosso conteúdo html. Title.name, por sua vez, nos retorna o conteúdo/nome encontrado nessa tag, como pode ser observado na figura abaixo:

Como é possível notar, nossos elementos html da página se transformaram em atributos do objeto soup. Além, outros filtros que podem ser feitos são a busca por links nas tags <a>
![]()
e a busca de todo o texto da página, utilizando o método get_text() (no contexto, (soup.get_text())).
Com esses conhecimentos, já é possível fazer buscas interessantes nos sites da web. Use sua imaginação, verifique suas necessidades e confira a documentação da Beautiful Soup para realizar os seus projetos. Lembre-se apenas de cuidar o tipo de informação que você está analisando. https://www.crummy.com/software/BeautifulSoup/bs4/doc/
Bokeh
Esta é uma biblioteca para visualização interativa de dados, usando HTML e Javascript para fornecer seus gráficos. Ela é relativamente simples de se utilizar e permite a criação de diversos tipos de gráficos.
Geralmente, inicia-se com a importação (from bokeh.plotting import figure, show), a criação de um plot (plot = figure(), com parâmetros variados para figure: title, plot_width, plot_height, x_axis_label, y_axis_label, etc.), um renderizador de linhna (p.line(), informando os valores x e y como vetores, legend_label, line_width) e a chamada para sua exibição (show(plot)). Por exemplo,
Código:
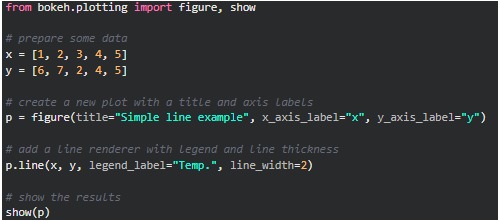
Gráfico:
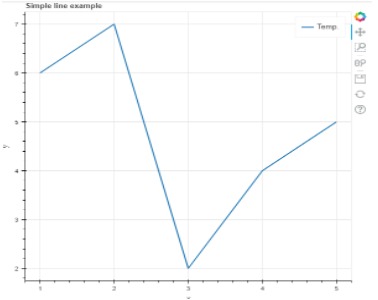
(Fonte: documentação)
A Bokeh possui uma documentação completa que auxiliará na criação e customização dos gráficos que precisarmos criar:
https://docs.bokeh.org/en/latest/docs/first_steps.html
Outras bibliotecas
Pandas
Pandas é um pacote que auxilia na manipulação de dados e também já foi citada em uma redação anterior. Fornece estruturas de dados rápidas, flexíveis e expressivas projetadas para tornar o trabalho com dados “relacionais” ou “rotulados” fácil e intuitivo. Ele tem como objetivo ser o bloco de construção fundamental de alto nível para fazer análises de dados práticos e do mundo real em Python.
Com a Pandas é mais fácil lidar com planilhas excel e tabelas sql, dados de matrizes e trabalha com data frames. Ela é construída a partir do NumPy, outra biblioteca, esta, para lidar com vetores e matrizes de forma fácil e eficiente.
Scikit Learn
É uma biblioteca de aprendizado de máquina de código aberto que oferece suporte ao aprendizado supervisionado e não supervisionado. Ele também fornece várias ferramentas para ajuste de modelo, pré-processamento de dados, seleção e avaliação de modelo e muitos outros utilitários. Ela fornece diversos métodos e algoritmos para lidar com machine learning.
PyGame
É uma biblioteca de jogos multiplataforma que permite a criação de interfaces gráficas para jogos de maneira simples. Ela fornece acesso a áudios, controles, etc.
Alguns jogos criados usando a biblioteca:
Wandering Soul

Super potato bruh

e Drawn Down Abyss

Arrow
A Arrow é uma biblioteca que auxilia no uso de datas e horas. Com ela é possível criar, alterar, remover e converter datas e horas, de forma muito mais fácil e rápida, utilizando muito menos código do que seria necessário para trabalhar com esses dados. Confira a documentação em https://pypi.org/project/arrow/.
Esses foram alguns exemplos de bibliotecas Python que podem ser úteis em seus projetos. Vá além de seus usos básicos e se aventurem na sua documentação para conhecer novos usos e possibilidades que tornaram seus projetos mais dinâmicos e interessantes. Bons estudos!
Referências:
- https://www.treinaweb.com.br/blog/qual-a-diferenca-entre-framework-e-biblioteca
- https://pillow.readthedocs.io/en/stable/
- https://www.tutorialspoint.com/python_pillow/python_pillow_quick_guide.htm
- https://www.crummy.com/software/BeautifulSoup/bs4/doc/
- https://acervolima.com/python-visualizacao-de-dados-usando-bokeh/
- https://www.vooo.pro/insights/visualizacao-interativa-de-dados-usando-bokeh-em-python/
- https://terminalroot.com.br/2019/12/as-30-melhores-bibliotecas-e-pacotes-python-para-iniciantes.html
- https://pandas.pydata.org/docs/getting_started/overview.html
- https://scikit-learn.org/
- https://minerandodados.com.br/cafe-com-codigo-06-introducao-machine-learning-com-scikit-learn/
- https://kenzie.com.br/blog/pygame/
- https://www.pygame.org/
- https://pypi.org/project/arrow/
- https://arrow.readthedocs.io/en/latest/
Raíssa Arantes


