
Nesta edição do PET Redação, vamos falar um pouquinho sobre programação de baixo nível. Isso quer dizer que a programação é ruim? Não, nada disso! Programação de baixo nível se trata de usarmos uma linguagem de programação que segue as características de estrutura do computador. Para isso, utilizaremos o software MARS (MIPS Assembler and Runtime Simulator) e a arquitetura MIPS32.
MARS é um ambiente de desenvolvimento integrado (IDE) destinado a estudos da arquitetura MIPS monociclo. Em conjunto com o software, nas disciplinas de Organização de Computadores e Arquitetura de Computadores, é utilizado o livro do Patterson, Organização e Arquitetura de Computadores.
A ferramenta MARS é um programa desenvolvido em Java e a partir do release 4.0, contém 155 instruções básicas da arquitetura MIPS, aproximadamente 370 pseudo-instruções, 17 funções syscalls para o console e entrada e saída de dados, outras 22 funções syscalls para outros usos como o MIDI output, para as saídas de mídia, geração de números aleatórios, entre outras tantas funções que vamos ver ao longo do texto.
Como podemos ver com essa breve introdução, a ferramenta é bem completa e proporciona ao usuário uma ótima noção do que acontece no processador. Então, basta fazer o download do software e começar a programar em Assembly.
Assembly é o que, no mundo da computação, chamamos de linguagem de montagem. É, basicamente, uma linguagem intermediária entre as linguagens de programação que nós usuários usamos e o que o computador interpreta.
O compilador (GCC, por exemplo) interpreta o nosso código em linguagem de alto nível (C, C++) e gera um arquivo do programa traduzido para o assembly da arquitetura em que o programa está sendo rodado. Nós podemos gerar o arquivo do assembly com o GCC mandando a flag -S junto do código para compilar. Nesse caso, estaremos gerando um assembly da arquitetura x86, que é a arquitetura da maioria dos computadores de hoje em dia.
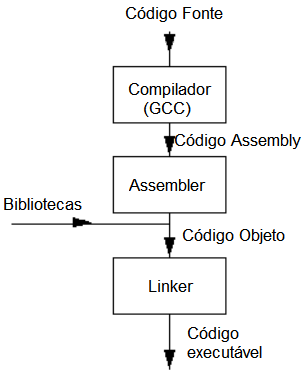
A imagem acima mostra exatamente o que acontece com um programa quando ele é compilado. O compilador recebe o código fonte (arquivo.c) e gera um código assembly (arquivo.s) a partir dele. Depois, o Assembler vai interpretar o código assembly do código fonte e, com as bibliotecas, vai gerar um código objeto (arquivo.o). Esse código objeto é um aglomerado de 0s e 1s referentes ao nosso programa. Depois do código objeto ser montado, o Linker vai pegar todos os códigos objetos que o programa tiver, caso tenha mais do que um, e vai montar um código executável (arquivo.exe). É basicamente isso o que acontece com um programa ao ser compilado.
O foco desse texto é aprender e entender como funciona um código Assembly. Por isso vamos nos basear no software MARS e na arquitetura MIPS32 para isso. O software está disponível para download no site dos desenvolvedores logo abaixo.
Assim que você abrir o MARS, vai se dar de cara com uma interface bem comum, até. O software tem uma estrutura bem parecida com outras IDEs. Como a ferramenta é feita para fins educativos da arquitetura MIPS32, a IDE tem alguns elementos bem peculiares.
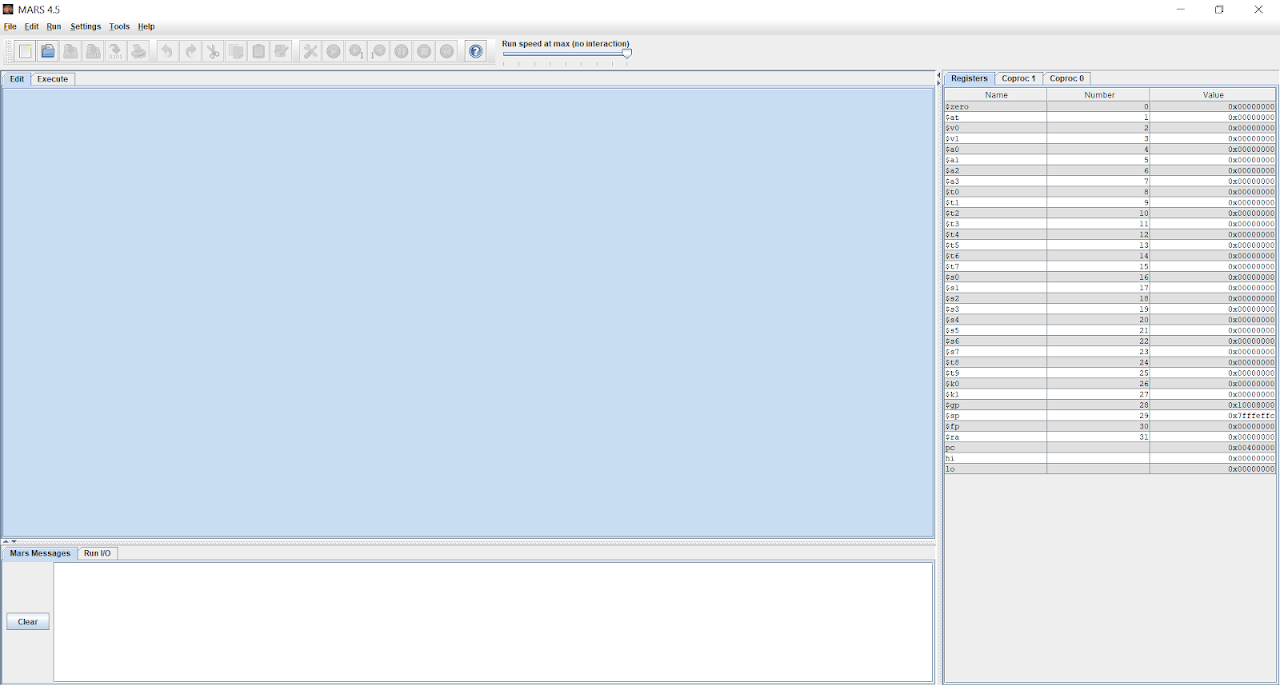
Em nossa direita é possível ver uma lista de elementos estranhos, com os cabeçalhos “Name”, “Number” e “Valor”. Cada elemento dessa lista representa um registrador e, essa lista, está representando o banco de registradores do processador.
Os campos “Name” e “Number” servirão para referenciarmos os nossos registradores no nosso código, já o campo “Value”, armazenará algum dado que quisermos colocar.
Abaixo do espaço azul há uma caixa em branco com o botão “Clear” à sua esquerda. Esta caixa é o console da IDE. Nela, vamos receber respostas do programa, solicitar entrada de dados pelo console e afins.
E por último, mas não menos importante, temos esse espaço em azul que é o editor de texto.
Para criarmos um novo arquivo, basta clicarmos no primeiro ícone da tabela de acesso rápido, ou ir em ‘File>New’. Após criarmos um arquivo em branco, o nosso editor vai ficar desse jeito.
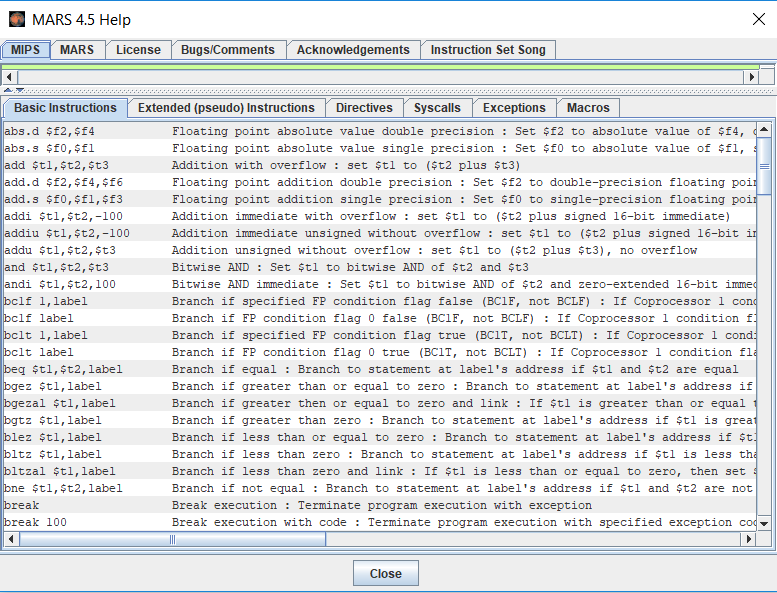
Com um arquivo criado na IDE, podemos começar a escrever alguns códigos. Para ajudarmos-nos, é aconselhável usar o Help. Apertando F1 temos acesso a ele.
A janela de Help é essencial no aprendizado da ferramenta pois nele obtemos acesso a todas aquelas instruções as quais comentei no começo do texto. Obtemos acesso às syscalls, às diretivas, às pseudo-instruções e até às macros. Não veremos tudo isso nesse texto, mas veremos uma boa parte.
Então, como começamos a escrever um código Assembly? Para começarmos com um código assembly, temos que entender como as instruções funcionam.
Em uma instrução temos dois elementos principais: O mnemônico e os operandos.
O mnemônico é o “nome” da instrução, vamos dizer assim, e os operandos são os nomes ou números dos registradores nos quais estamos operando.
Um exemplo de instrução é o ‘add’. Essa instrução realiza uma soma de dois registradores e armazena em um terceiro registrador. A instrução fica assim:
add $t2, $t0, $t1
Nesse caso, estamos fazendo uma soma do conteúdo do registrador $t0 com o conteúdo do registrador $t1 e armazenando o resultado em $t2. O registrador que recebe o resultado é o primeiro a ser referenciado na expressão, seguido pelos registradores que farão a operação.
Já sabemos como funciona uma instrução de soma, vamos colocá-la na ferramenta e testar para ver o que vai dar.
Antes da minha operação de soma, coloquei duas outras instruções para carregar valores nos registradores $t0 e $t1. Após carregar esses dois valores nos meus registradores, eu posso realizar a instrução add e ver o que vai acontecer.
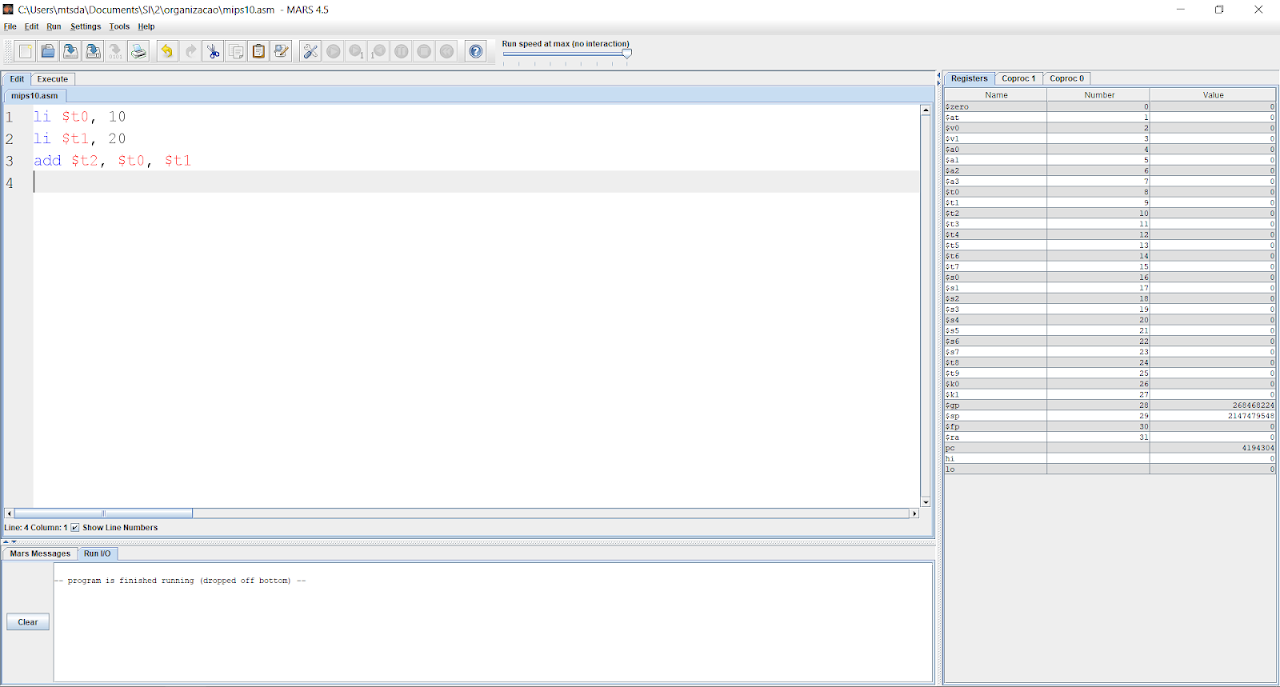
Para compilar o código que estamos escrevendo, primeiro é necessário salvar o arquivo. Após salvar o arquivo, para compilar basta apertar F3 ou ir em ‘Assemble>Run’.
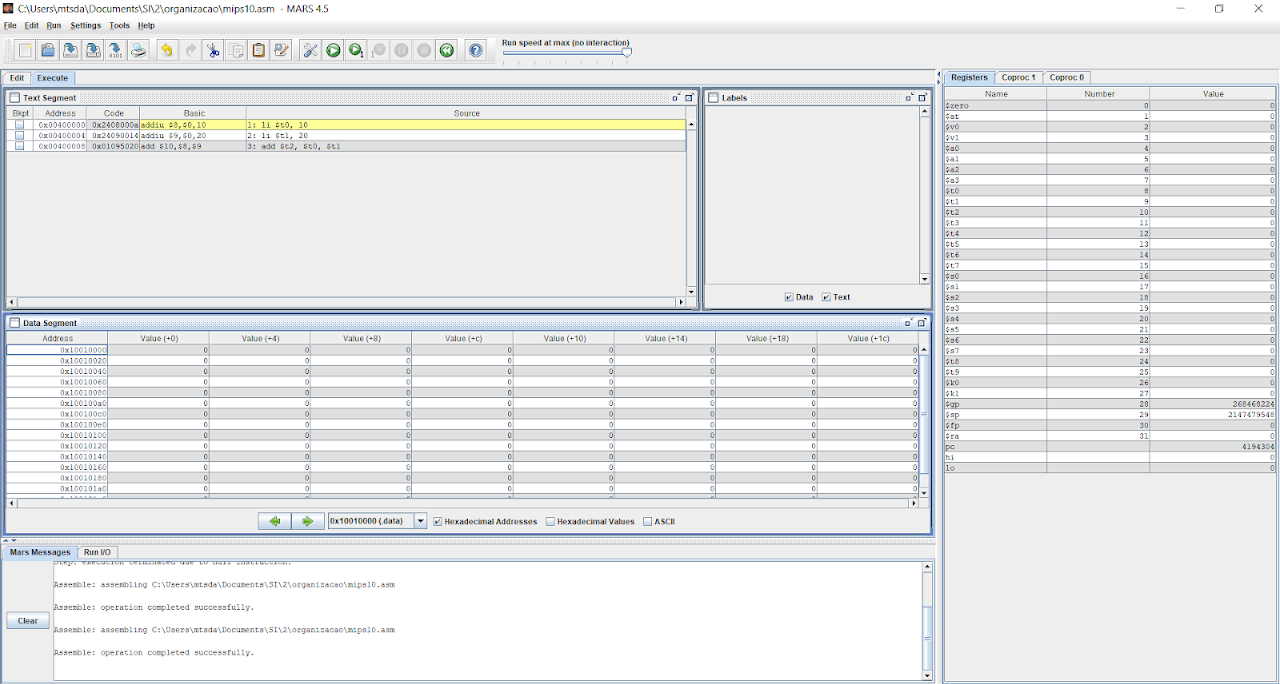
Após compilar o programa, abre uma nova tela com esses elementos mostrados acima. Nesta tela podemos ver que temos outros dois segmentos que não conhecíamos, os segmentos de texto e de dados. O segmento de texto contém todas as nossas instruções do nosso código. Cada instrução terá um endereço, um código e para facilitar a compreensão na ferramenta, temos o campo ‘Source’, que contém exatamente o que está marcado naquela linha. Já o segmento de dados, representa a nossa memória. Mais adiante, nesse texto, veremos instruções que irão gravar na memória.
Podemos ver na imagem acima que nosso segmento de texto contém três instruções a serem executadas. E são exatamente as instruções que colocamos no nosso editor de texto, lá na outra tela. É possível acessar aquela tela apenas clicando no botão ‘Edit’, bem à esquerda , abaixo da barra de acesso rápido.
Mas e agora, como fazemos para ver o programa sendo executado? Bom, há duas formas de executar o programa. Podemos executá-lo instrução a instrução ou podemos executá-lo normal. Se apertarmos a tecla F5 ou formos em ‘Run>Go’, veremos que o programa irá executar até o fim, sem parar, mostrando os resultados no nosso banco de registradores à direita do segmento de dados.
Os valores de $t0, $t1 e $t2 foram alterados para os valores que colocamos em $t0 e $t1, e o valor da soma em $t2.
Se pressionarmos a tecla F7 ou acessar no menu a opção Run>Step, executaremos uma instrução de cada vez. Executar desta maneira é muito bom para entender exatamente o que está acontecendo no processador. É bastante útil, também, para debugar código, pois veremos todas as instruções do programa sendo executadas uma por vez, conseguindo assim detectar o bug para corrigir exatamente onde nos é conveniente.
Agora voltando ao nosso código, vemos que ele parece estar “solto” ali no editor de texto, não é? Pois bem, a partir de agora utilizaremos as diretivas para organizar o nosso código.
As diretivas servirão para dizer ao assembler onde ele deverá escrever aquele dado.
As duas principais diretivas são ‘.text’ e ‘.data’, e servirão para dizer se estamos escrevendo código para o segmento de texto ou para o segmento de dados, respectivamente. Podemos consultar todas as diretivas do MIPS no Help pressionando F1 e indo na aba ‘Directives’.
Para entendermos melhor o que essas duas diretivas fazem, vamos olhar outro código. Vejamos este código de Hello World! em Assembly.
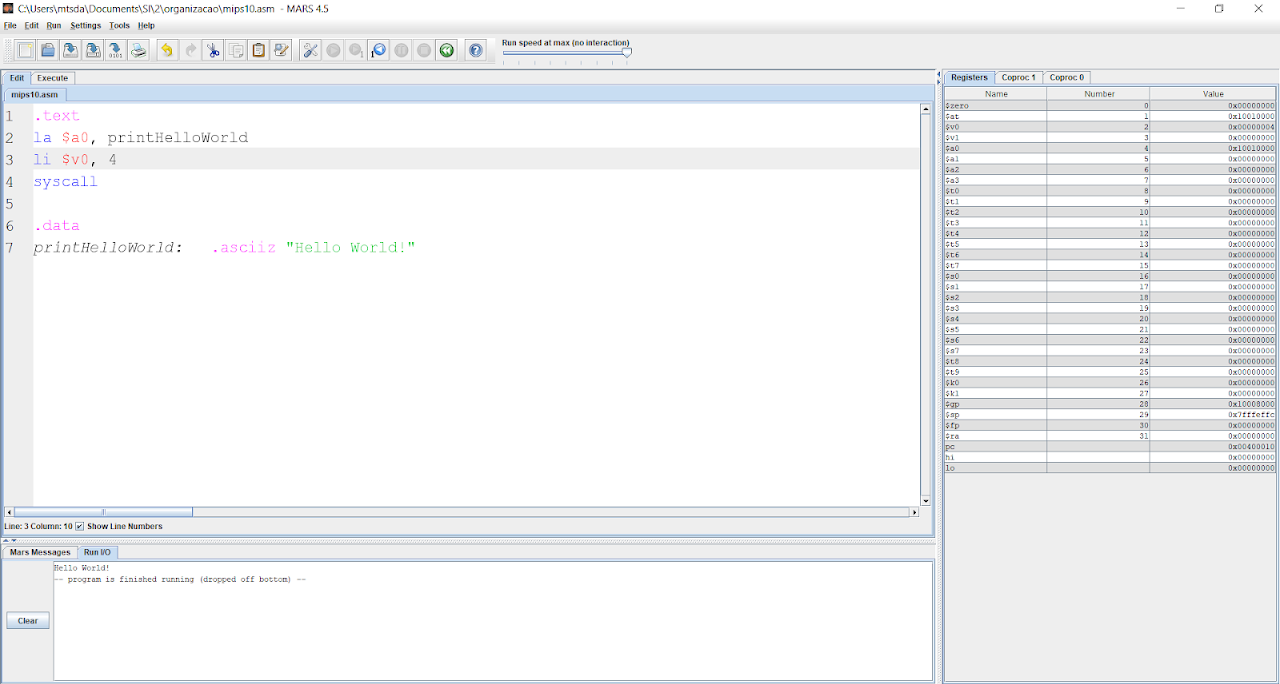
O que há de novo neste código? Podemos ver as diretivas, como explicado anteriormente, mas também podemos ver novos elementos. Temos a instrução la, que vai nos servir para armazenar o endereço de algum elemento em um registrador específico. Nesse caso, estamos pegando o endereço do rótulo ‘printHelloWorld’. Um rótulo é como se fosse uma marcação daquele endereço específico. E com essa marcação, podemos acessar esse endereço por esse rótulo.
Depois, temos a primeira syscall. Uma syscall é uma chamada do sistema, literalmente falando. Como ela funciona? Essa chamada do sistema tem dois registradores padrão de argumentos. O $a0 e o $v0. Para essa syscall, que é de imprimir uma string no console, enviamos o endereço da string que queremos imprimir para $a0 e o código da operação enviamos para $v0. Esse código da operação podemos consultar no Help apertando F1 e indo na aba Syscalls. Após enviarmos os valores para os registradores de argumento da syscall, fazemos uma chamada com o comando syscall no nosso código.
Também temos uma nova diretiva, o .asciiz, que é a diretiva responsável por representar os caracteres da string a seguir em ASCII com a terminação ‘\0’.
Fora os novos elementos do código, é visível que ele está melhor estruturado, separando o que é do segmento de texto e o que é do segmento de dados.
Após compilar o nosso código, na nossa tela de execução teremos algo diferente. O nosso segmento de dados não está mais vazio. Agora, contém nele a nossa string “Hello World!”, que enviamos com a diretiva .asciiz. Podemos executar o programa pressionando o F5 ou através do F7 e ver como o processador faz a execução de cada instrução.
Se prestar atenção, veremos que no segmento de dados existem alguns valores bem grandes nos primeiros endereços. E se clicarmos no ASCII, abaixo do segmento de dados, veremos estes valores em ASCII. Nos primeiros endereços estão armazenados todos os caracteres em código ASCII da nossa string.
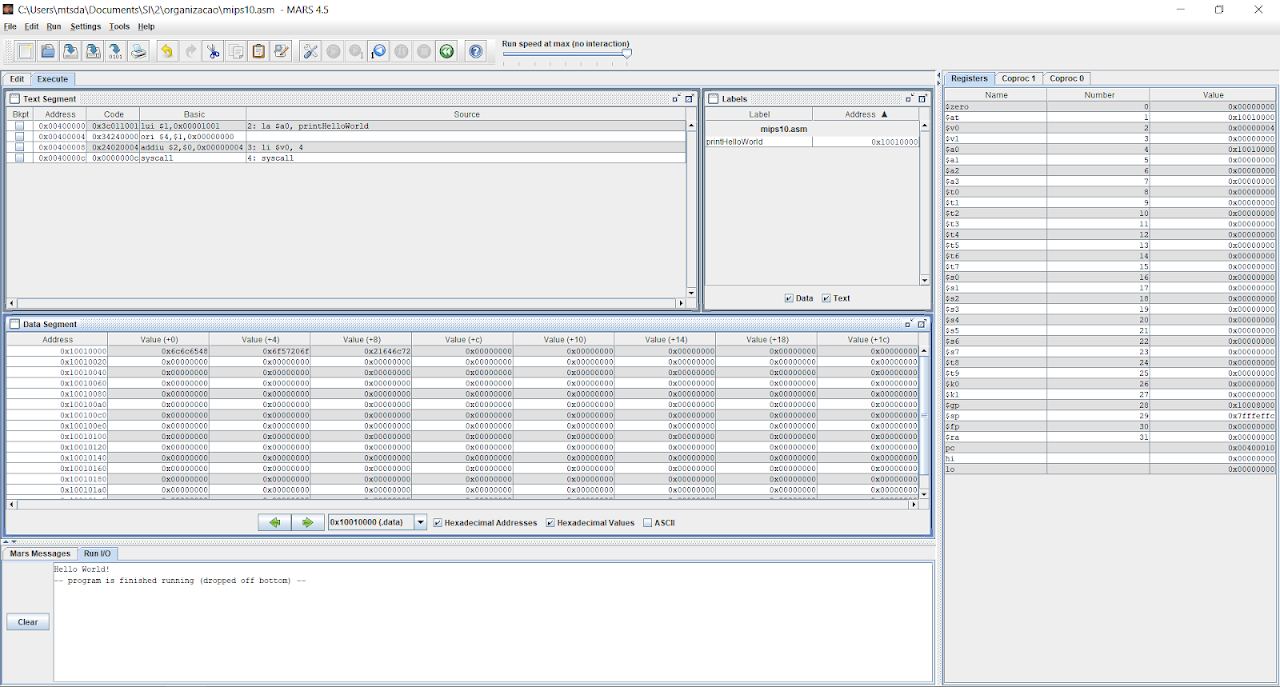
Após o término da execução teremos no nosso console a string que mandamos imprimir e também poderemos ver dois valores em nossos registradores $a0 e $v0. Em $a0 observamos o valor 0x10010000, que corresponde ao endereço de começo da nossa string e, em $v0, o valor 0x00000004, que corresponde ao valor 4 que colocamos nele para executar a operação de imprimir string.
Até agora vimos como o software MARS funciona, como as instruções da arquitetura MIPS funcionam e outras funções relacionadas a entrada e saída de dados. O que veremos agora serão as estruturas básicas de um programa representado em Assembly.
Estruturas sequenciais:
As estruturas sequenciais são representadas da mesma forma que estruturamos essas em uma linguagem do paradigma procedural. Cada instrução é posicionada uma abaixo da outra. Vamos ver um exemplo de uma estrutura sequencial em Assembly.
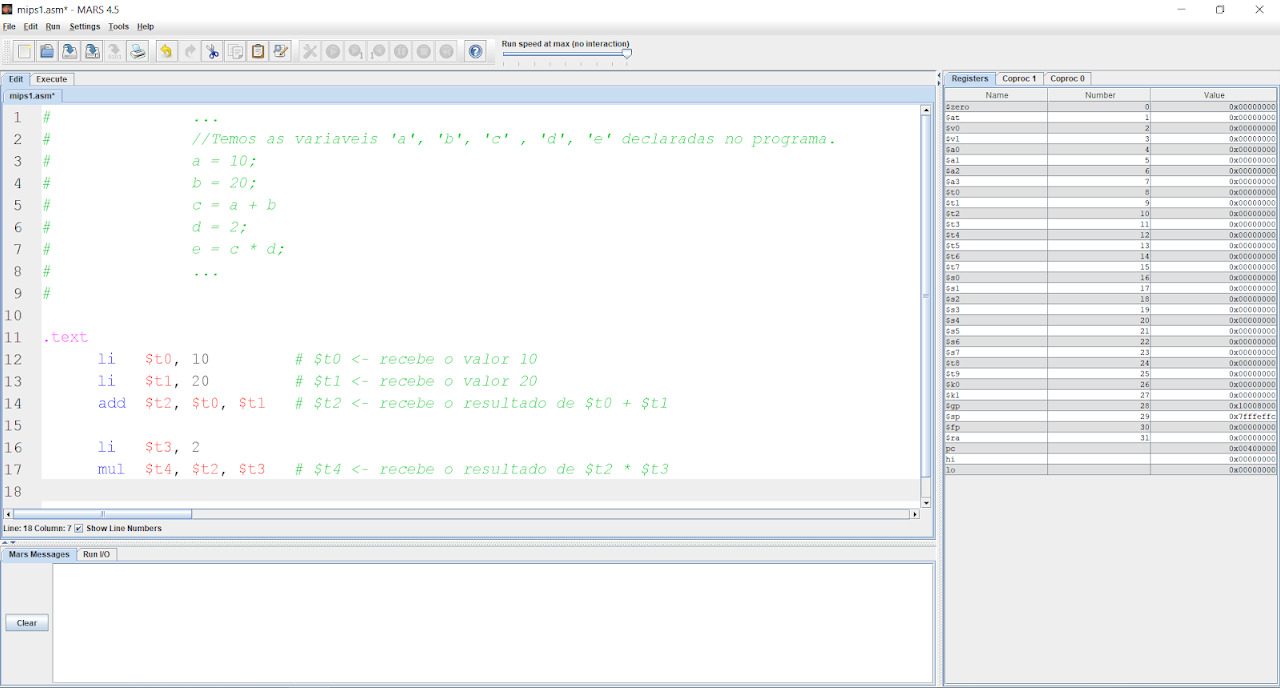
No código acima, vemos que no código escrito em C, estamos atribuindo valores para tais variáveis, operando estes valores e atribuindo para outras variáveis. Como é possível ver, no assembly é bem parecido. Nesse caso, os nossos registradores $t0, $t1, $t2, $t3, e $t4 representam as variáveis ‘a’, ‘b’, ‘c’, ‘d’, e ‘e’, respectivamente.
Estruturas condicionais:
Nas estruturas condicionais temos os ‘if’s’ , ‘elses’ e o switch. Essas estruturas serão construídas em assembly com instruções de desvios, chamadas de branch. Também devemos estruturar o código de forma a executar apenas os da condição, entretanto, como fazer isto? Bom, há duas formas de fazer isso, podemos estruturar o código para que verifique se a condição é satisfeita e salte para as instruções ou podemos estruturar o código para a condição que não é satisfeita e fique executando na sequência das instruções.
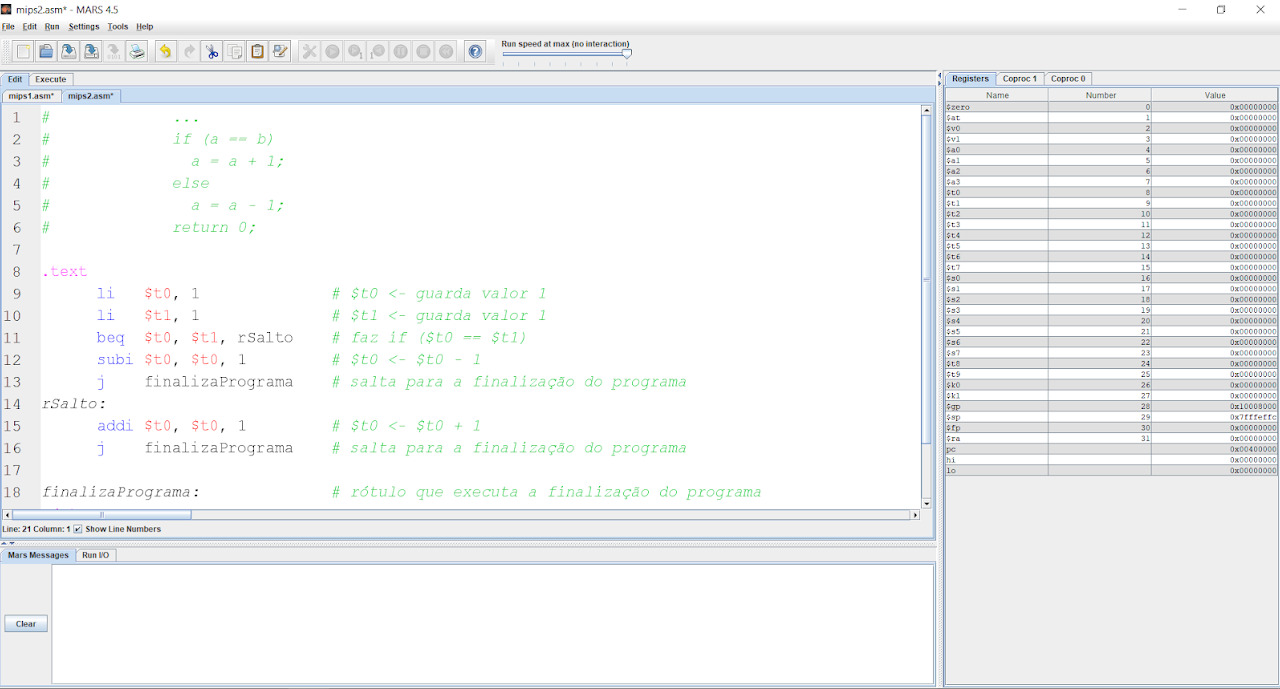
A primeira forma de fazermos uma estrutura condicional é usando a instrução beq (Branch if equal). A instrução beq verifica se os registradores possuem a mesma informação. Caso seja verdade, a instrução salta para o rótulo relacionado a ela.
Podemos ver no exemplo abaixo:
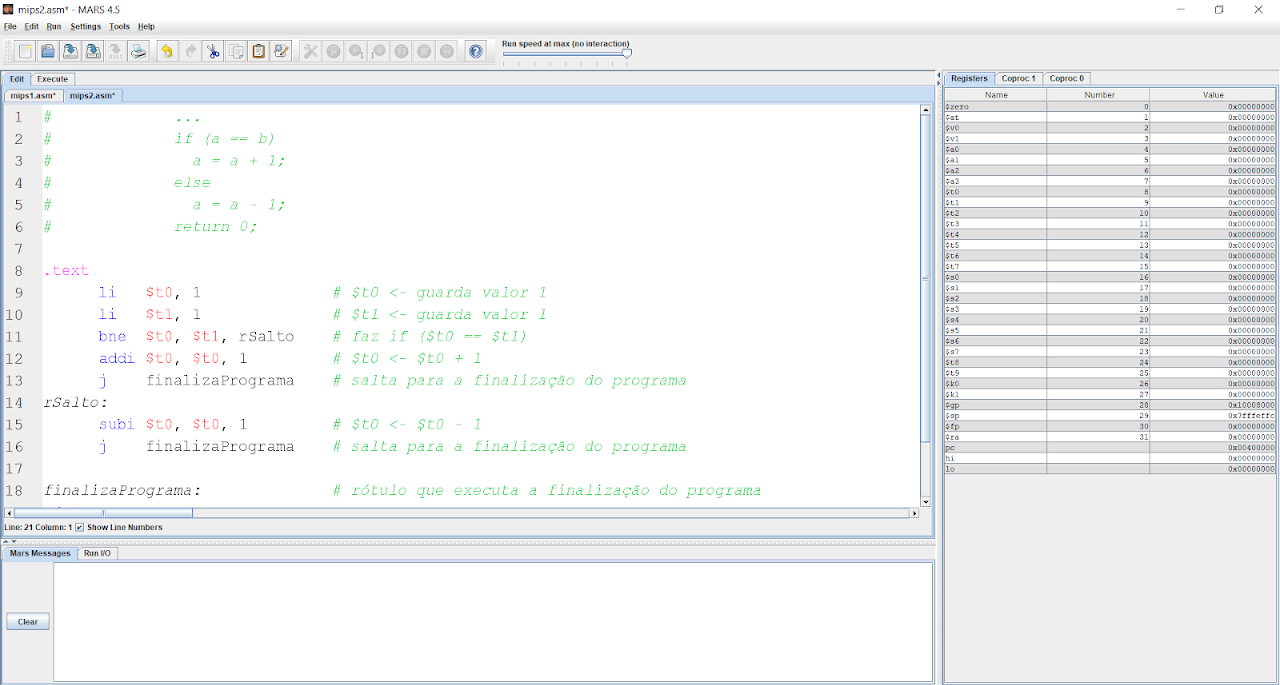
A outra forma de estruturarmos um if-else é com a instrução bne (Branch if not equal). Essa instrução verifica se os registradores que estão operando são diferentes, caso sejam, a instrução realizará um salto para o rótulo relacionado.
A seguir, veja o exemplo na imagem:
Nos dois exemplos, vemos a instrução j, que é uma instrução de salto incondicional. Esta instrução realiza um salto para o rótulo relacionado a ela que contém o endereço de salto.
A estruturação de um switch na linguagem assembly usa várias instruções branch pois essa estrutura pode ter mais de dois resultados possíveis. Vejamos um exemplo de switch com 3 casos:
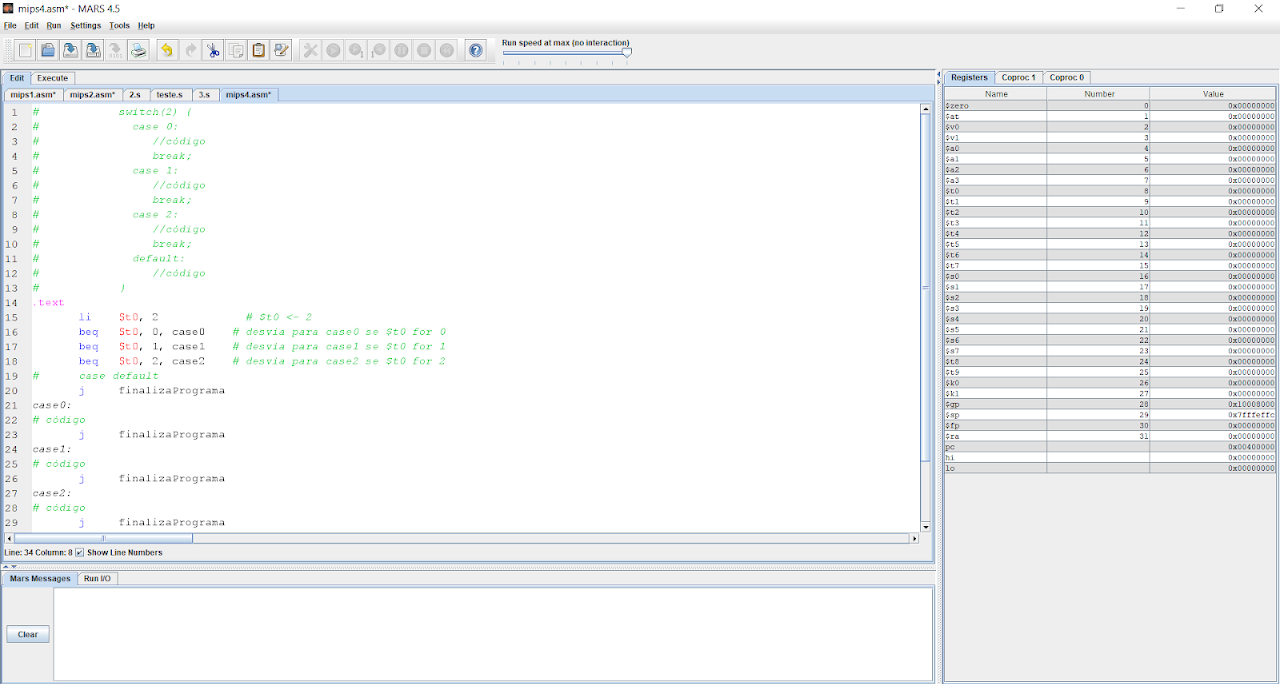
Como pode ser visto no exemplo, são várias instruções branch em sequência que verificam o valor do case. Neste caso, há o valor 2 no nosso switch, que fará com que realize o código do case2. Caso nenhum dos casos seja satisfeito, o programa realiza as instruções do default, colocado logo abaixo de todos os beq’s.
Estruturas de repetição:
As estruturas de repetição na linguagem Assembly utilizam-se de elementos que compõem as nossas outras estruturas. Como realizar uma operação n vezes? Em todos os casos haverá uma condição de parada. E para verificarmos uma condição, utilizamos as instruções branch.
“A soma é realizada 10 vezes…”
Nesse caso, o nosso laço irá iterar 10 vezes, certo? E como essa repetição funciona? Ela precisa executar aqueles passos contidos dentro da estrutura do laço e voltar para o começo do laço, correto?
Bom, para estruturarmos essa “volta para o começo do laço”, usamos a instrução j e endereçamos um rótulo do começo do laço. Nos exemplos abaixo dá pra ver as três estruturas de repetição: do-while, while e for.



Apesar das três estruturas serem bem parecidas, elas diferem no posicionamento do incremento da variável controladora do laço. Estes exemplos são básicos, apenas para situar você, leitor, sobre como funcionam laços em uma linguagem de montagem.
O MARS possui várias ferramentas que auxiliam no desenvolvimento de programas mais elaborados. Acessando o menu ‘Tools’, podemos ver essas ferramentas. Algumas delas são bem interessantes como a MIPS X-Ray, que mostra a propagação da instrução corrente no processador. O Bitmap Display é um simulador de uma interface gráfica, o interessante nessa ferramenta, implementando um programa para ser executado com essa interface, é ver como as GPUs funcionam e ter uma ideia de como funciona uma placa de vídeo. O Keyboard and Display MMIO Simulator simula as entradas do teclado em tempo real do programa. Estas são algumas das ferramentas que o software traz para o usuário estudar e aprender a programação de nível mais baixo.
Além das ferramentas e de todas as funcionalidades que vimos no texto, o software também oferece as funções e registradores de ponto flutuante. Acessando a aba ‘Coproc 1’, obtemos acesso a esses registradores. E as funções podem ser consultadas no menu Help, pressionando a tecla F1.
As funções de ponto flutuante operam apenas nos registradores $fn. Apenas as instruções de conversão utilizam os dois tipos de registradores.
Caso você tenha curiosidade de conhecer um pouco mais sobre a ferramenta, disponibilizo abaixo o link do meu GitHub, que contém os trabalhos que realizei na disciplina de Organização de Computadores. Nestes trabalhos eu utilizei tanto os simuladores de interface gráfica quanto os registradores de ponto flutuante.
-
-
“Computer and Organization Design” – David A. Patterson, John L. Hennessy.